
An In-Depth Look at Druid’s Structure and Functionality
Introduction
Apache Druid has established itself as one of the most reliable and powerful real-time analytical data stores available today. Its architectural design is specifically tailored to support high levels of concurrency and deliver low-latency analytical queries, even when faced with the challenge of processing vast streams of data.
Exploring Druid’s Real-Time Capabilities
A frequent question from users centres around how Druid manages to efficiently handle a large number of simultaneous analytical queries, all while maintaining remarkable speed. This ability is essential for scenarios involving substantial and continuous flows of data, where responsiveness and scalability are key.
Key Concepts from the Foundational Druid Paper
The main ideas discussed in this section originate from the influential 2014 paper, “Druid: A Real-Time Analytical Data Store”. Contextual explanations accompany these concepts, illustrating how they translate to practical, real-world applications.
Note on Druid’s Evolution
It is worth noting that some aspects described here are based on the original 2014 paper. Since its publication, Druid has undergone significant development, with versions 0.22 and onwards introducing new components such as Overlord and MiddleManager nodes, enhancing the platform’s capabilities and robustness.
The Beginning
In 2004, Google revolutionised distributed data processing with the release of the MapReduce paper, which simplified large-scale data processing. This breakthrough inspired the creation of Apache Hadoop, which, together with the Hadoop Distributed File System (HDFS), became the foundation for batch-oriented big data analytics for over a decade.
Despite its widespread use, Hadoop’s batch-oriented MapReduce model was not designed for real-time analytics, resulting in high latency and slow responsiveness—conditions that are far from ideal for interactive analytical workloads.
This gap in real-time capabilities led Metamarkets (now known as Rill Data) to develop a solution for marketers seeking to analyse streaming data interactively. Their requirements included low query latency for instant insights, high concurrency to support many simultaneous users, and high availability to ensure minimal downtime.
No existing open-source tool met all these needs, prompting Metamarkets to create Druid—a distributed, fault-tolerant, column-oriented data store purpose-built for real-time analytics on massive event streams.
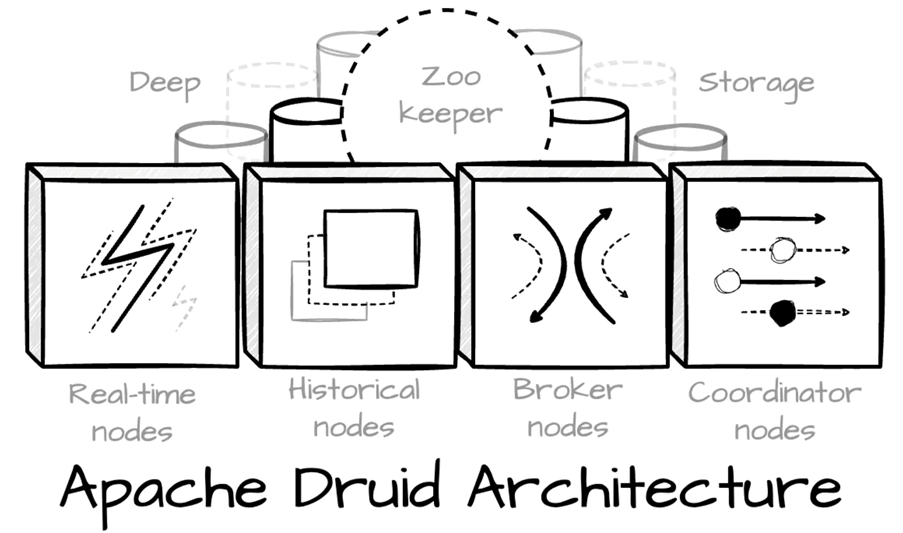
The Architecture
Druid employs a shared-nothing architecture, with each node operating independently and responsible for a specific aspect of ingestion, storage, or query processing.
At a high level, a Druid cluster consists of several node types:
- Real-time Nodes – Responsible for ingesting and indexing live event data.
- Historical Nodes – Load and serve immutable, persisted data segments.
- Broker Nodes – Route queries and aggregate results.
- Coordinator Nodes – Manage data distribution and replication.
- Overlord and MiddleManager Nodes (introduced in later versions) – Manage ingestion tasks.
Each node type has well-defined responsibilities, contributing to the system’s scalability, fault tolerance, and efficiency in executing queries.
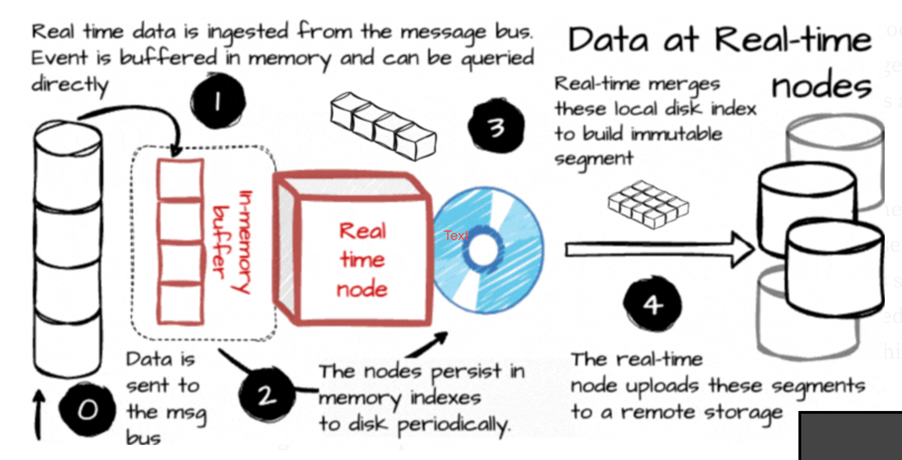
Real-Time Nodes
Real-time nodes simultaneously manage event ingestion and query availability, ensuring that newly ingested data is accessible for querying almost immediately.
- Ingestion – These nodes consume data streams, typically from Kafka, and maintain an in-memory index buffer for incoming events.
- Indexing – Data is initially stored in a row-based format in memory but is periodically persisted as a columnar segment on disk, either at scheduled intervals or after reaching a row count threshold.
- Persistence & Segmentation – Persisted data is converted into immutable segments, which are subsequently uploaded to deep storage solutions such as S3 or HDFS.
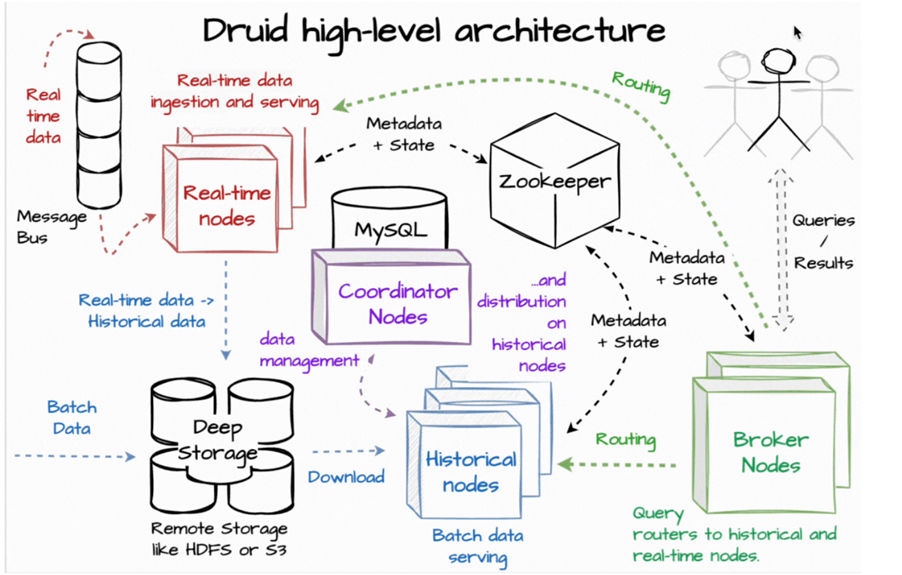
- Coordination – Nodes announce their status and active segments to Zookeeper, which acts as Druid’s metadata and coordination layer.
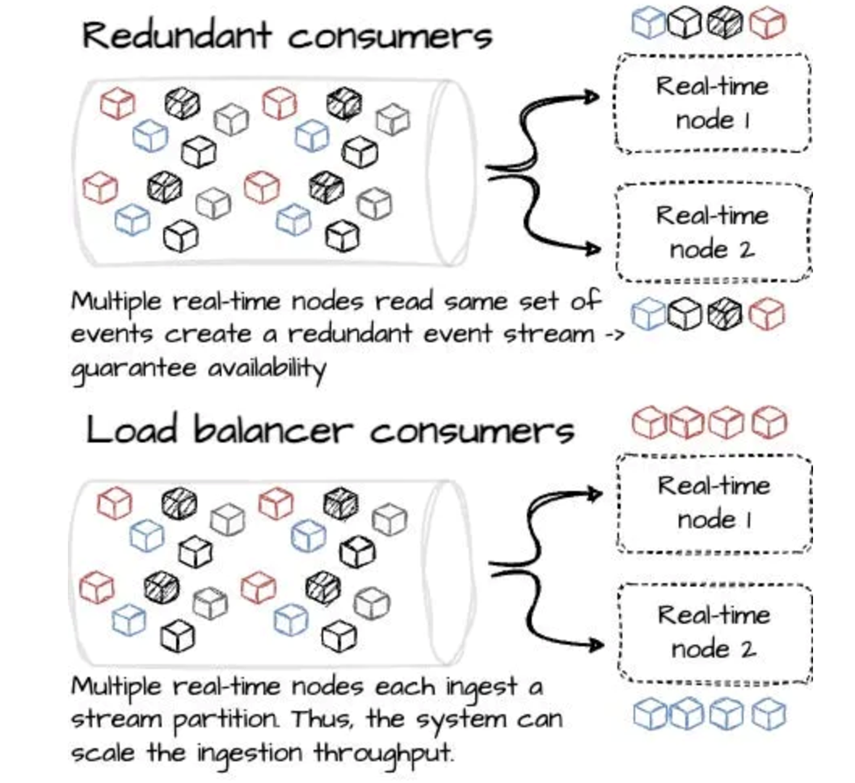
Integration with Kafka
Real-time nodes typically ingest data from Kafka topics, benefiting from several features:
- Kafka buffers events and maintains offsets to track consumption state.
- In the event of a failure, nodes can resume ingestion from the last committed offset, ensuring fault tolerance.
- Multiple nodes can redundantly consume from the same topic, enhancing resilience.
- Scalable throughput is achieved by partitioning ingestion across multiple nodes.
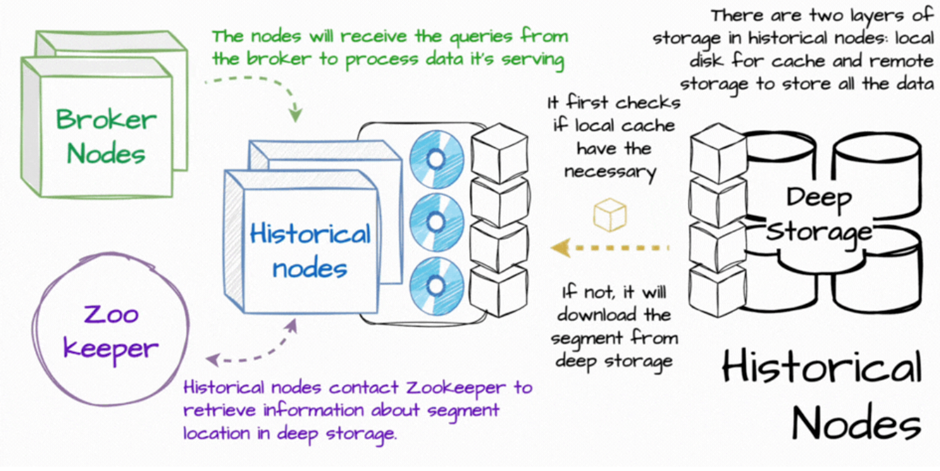
Historical Nodes
Historical nodes are tasked with serving immutable data segments that have been persisted and uploaded by real-time nodes.
- Segment Loading – Fetch segments from deep storage and cache them locally to improve read performance.
- Coordination with Zookeeper – Announce their availability and the segments they serve.
- Query Serving – Guarantee consistency and enable parallel reads, thanks to the immutability of the data.
- Tiering – Nodes can be organised into tiers, such as hot (high-performance, frequently accessed data) and cold (lower-cost, rarely accessed data), balancing performance and cost based on query patterns.
Broker Nodes
Broker nodes function as query routers and result aggregators within Druid’s architecture.
- A broker receives a user query and consults Zookeeper metadata to identify the required segments and their locations.
- The query is forwarded to the relevant real-time and historical nodes.
- Intermediate results are merged, and a unified response is returned to the user.
Caching
- Broker nodes use LRU caching to boost performance, storing results for immutable historical data.
- Real-time data is not cached to ensure query freshness.
- Caching can use either local heap memory or external solutions like Memcached.
- If Zookeeper fails, brokers rely on their last known metadata state to continue serving queries, maintaining high availability.
Coordinator Nodes
Coordinator nodes oversee data lifecycle management, replication, and load balancing across historical nodes.
- Assign new data segments to historical nodes.
- Remove outdated or expired segments.
- Replicate segments across nodes to maintain redundancy.
- Monitor and balance cluster load.
Only one coordinator node operates as the leader at any time, with others in standby mode. The coordinator references a rule table, stored in a MySQL metadata store, which defines segment replication, tiering, and retention or deletion policies. In essence, coordinator nodes serve as Druid’s control plane, mirroring the function of Kubernetes controllers by ensuring data distribution aligns with operational requirements.
Storage Format
In Druid, data is organised into segments, which serve as the atomic units of storage and distribution.
- Each data source comprises a collection of timestamped events.
- Data is partitioned into segments, typically containing 5–10 million rows each.
- Each segment is defined by a data source ID, time interval, and version, with newer versions representing fresher data.
Why Columnar Storage?
- Segments are stored in columnar format within deep storage, enabling efficient CPU usage by loading only necessary columns.
- Vectorised queries accelerate aggregation processes.
- Type-specific compression reduces both disk and memory footprint.
Druid’s mandatory timestamp column supports powerful time-based partitioning and retention policies, making it an excellent fit for time-series analytics.
Putting It All Together
- Data Ingestion – Real-time nodes read event streams from Kafka and store them in memory.
- Segment Creation – Data is periodically flushed to disk, converted to columnar format, and uploaded to deep storage.
- Query Routing – Broker nodes use Zookeeper metadata to route queries to the appropriate real-time and historical nodes.
- Data Serving – Historical nodes load immutable segments and serve queries in parallel for optimal performance.
- Cluster Coordination – Coordinator nodes manage data balance, replication, and retention policies across the cluster.
Conclusion
This thorough examination of Apache Druid’s real-time architecture demonstrates how it is purpose-built to deliver sub-second analytics on streaming data at scale. For further exploration, consider examining its counterpart, Apache Pinot, the real-time OLAP engine developed by LinkedIn.
Continue uncovering the systems that make real-time analytics possible.








