
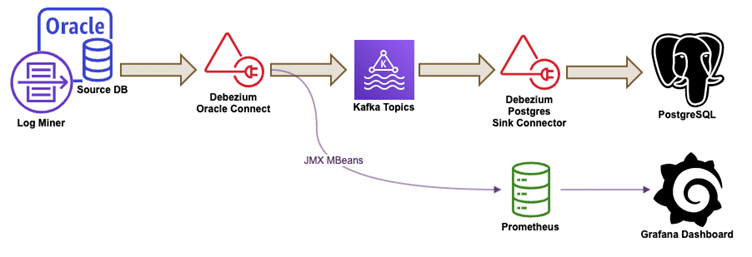
This Proof of Concept demonstrates Debezium’s ability to enable real-time data synchronization between Oracle and PostgreSQL databases through CDC. In addition to replicating data, the solution supports conditional data filtering. A secondary flow is also configured to support analytics and monitoring, feeding live stats into Grafana dashboards.
Simple diagram-
Configuration Steps
Following the different files, we will be using for this demo
Get Oracle Docker Image
Oracle docker images are not available in public Docker hub repository, it is hosted in Oracle’s own repository. Here are the steps to get the image
- Visit oracle container repo — https://container-registry.oracle.com/ords/f?p=113:1:117569610822412:::1:P1_BUSINESS_AREA:3
- Sign in
- Accept T&C for enterprise db
- Use the following command line commands to pull the image
- docker login container-registry.oracle.com (use the same user/password as web login)
- docker pull container-registry.oracle.com/database/enterprise:19.3.0.0
Create Debezium Connect Image
As Oracle is not open source, the Debezium connect image is not comes with Oracle driver integrated with it. Need to customise the image with Oracle driver & also Kafka connect for Sink Connector
Download Oracle driver & unzip at oracle_instantclient/ — https://download.oracle.com/otn_software/linux/instantclient/1914000/instantclient-basic-linux.x64-19.14.0.0.0dbru.zip
Download Sink connector & unzip at confluentinc-kafka-connect-jdbc-10.3.3/ — https://www.confluent.io/hub/confluentinc/kafka-connect-jdbc
Download Scripting dependency & unzip at debezium-scripting/ — https://repo1.maven.org/maven2/io/debezium/debezium-scripting/1.8.1.Final/debezium-scripting-1.8.1.Final.tar.gz
Download following groovy dependencies for filter expression at groovy/
https://repo1.maven.org/maven2/org/codehaus/groovy/groovy-jsr223/3.0.9/groovy-jsr223-3.0.9.jar
https://repo1.maven.org/maven2/org/codehaus/groovy/groovy-json/3.0.9/groovy-json-3.0.9.jar
https://repo1.maven.org/maven2/org/codehaus/groovy/groovy/3.0.9/groovy-3.0.9.jar
| ARG DEBEZIUM_VERSION | |
| FROM debezium/connect:$DEBEZIUM_VERSION | |
| ENV KAFKA_CONNECT_JDBC_DIR=$KAFKA_CONNECT_PLUGINS_DIR/kafka-connect-jdbc | |
| ARG JMX_AGENT_VERSION | |
| RUN mkdir /kafka/etc && cd /kafka/etc &&\ | |
| curl -so jmx_prometheus_javaagent.jar \ | |
| https://repo1.maven.org/maven2/io/prometheus/jmx/jmx_prometheus_javaagent/$JMX_AGENT_VERSION/jmx_prometheus_javaagent-$JMX_AGENT_VERSION.jar | |
| COPY config.yml /kafka/etc/config.yml | |
| USER kafka | |
| # Add Oracle client and drivers | |
| COPY oracle_instantclient/xstreams.jar /kafka/libs | |
| COPY oracle_instantclient/ojdbc8.jar /kafka/libs | |
| # Add Confluent kafka connect for jdbc sink connector | |
| COPY confluentinc-kafka-connect-jdbc-10.3.3/lib/*.jar /kafka/connect/kafka-connect-jdbc/ | |
| COPY confluentinc-connect-transforms-1.4.2/lib/*.jar /kafka/connect/kafka-connect-transforms/ | |
| # Add filter dependencies | |
| COPY debezium-scripting/*.jar /kafka/connect/debezium-connector-oracle/ | |
| COPY groovy/*.jar /kafka/connect/debezium-connector-oracle/ |
Run Containers
Following is the docker compose file to initiate all required docker containers.
If you are running Docker Desktop, it may choke the resources as there are seven Docker containers in the compose file. You may need to increase the memory to 6g in the Docker Desktop settings.
Oracle container may take ~20 minutes to spin up. Use volume mount for oracle container to faster initialisation second time onwards.
| version: ‘2’ | |
| services: | |
| oracledb19: | |
| image: container-registry.oracle.com/database/enterprise:19.3.0.0 | |
| ports: | |
| – 1521:1521 | |
| environment: | |
| – ORACLE_PWD=top_secret | |
| volumes: | |
| – /tmp/oradata:/opt/oracle/oradata | |
| postgres: | |
| image: debezium/postgres:9.6 | |
| ports: | |
| – 5432:5432 | |
| environment: | |
| – POSTGRES_USER=postgresuser | |
| – POSTGRES_PASSWORD=postgrespw | |
| – POSTGRES_DB=inventory | |
| zookeeper: | |
| image: debezium/zookeeper:${DEBEZIUM_VERSION} | |
| ports: | |
| – 2181:2181 | |
| – 2888:2888 | |
| – 3888:3888 | |
| kafka: | |
| image: debezium/kafka:${DEBEZIUM_VERSION} | |
| ports: | |
| – 9092:9092 | |
| links: | |
| – zookeeper | |
| environment: | |
| – ZOOKEEPER_CONNECT=zookeeper:2181 | |
| depends_on: | |
| – zookeeper | |
| prometheus: | |
| build: | |
| context: debezium-prometheus | |
| args: | |
| PROMETHEUS_VERSION: v2.26.0 | |
| ports: | |
| – 9090:9090 | |
| links: | |
| – connect | |
| depends_on: | |
| – connect | |
| grafana: | |
| build: | |
| context: debezium-grafana | |
| args: | |
| GRAFANA_VERSION: 7.5.5 | |
| ports: | |
| – 3000:3000 | |
| links: | |
| – prometheus | |
| depends_on: | |
| – prometheus | |
| environment: | |
| – DS_PROMETHEUS=prometheus | |
| connect: | |
| image: debezium/connect-with-oracle-jdbc:${DEBEZIUM_VERSION} | |
| build: | |
| context: debezium-with-oracle-jdbc | |
| args: | |
| DEBEZIUM_VERSION: ${DEBEZIUM_VERSION} | |
| JMX_AGENT_VERSION: 0.15.0 | |
| ports: | |
| – 8083:8083 | |
| – 5005:5005 | |
| – 1976:1976 | |
| links: | |
| – kafka | |
| depends_on: | |
| – kafka | |
| environment: | |
| – BOOTSTRAP_SERVERS=kafka:9092 | |
| – GROUP_ID=1 | |
| – CONFIG_STORAGE_TOPIC=my_connect_configs | |
| – OFFSET_STORAGE_TOPIC=my_connect_offsets | |
| – STATUS_STORAGE_TOPIC=my_connect_statuses | |
| – LD_LIBRARY_PATH=/instant_client | |
| – KAFKA_DEBUG=true | |
| – DEBUG_SUSPEND_FLAG=n | |
| – JAVA_DEBUG_PORT=0.0.0.0:5005 | |
| – KAFKA_OPTS=-javaagent:/kafka/etc/jmx_prometheus_javaagent.jar=8080:/kafka/etc/config.yml | |
| – JMXPORT=1976 | |
| – JMXHOST=localhost |
export DEBEZIUM_VERSION=1.8
docker-compose -f docker-compose-oracle.yaml up — build
Setup Log Miner in Oracle
This process enables sets up the process of LogMining in Oracle. It basically sets up the users & required credentials to facilitate LogMining.
docker exec -it debezium_oracledb19_1 /bin/bash
mkdir /opt/oracle/oradata/recovery_area
curl https://raw.githubusercontent.com/debezium/oracle-vagrant-box/main/setup-logminer.sh | sh
Populate Dummy Data
In order to play around the CDC capabilities, let’s populate the database with few tables & records. The following script creates tables CUSTOMERS, ORDERS, PRODUCTS, PRODUCTS_ON_HAND and populates few records in each tables.
cat inventory.sql | sqlplus debezium/dbz@//localhost:1521/ORCLPDB1
Register Connectors
This connector ‘inventory-connector’ is a OracleConnector which start the LogMiner process, detects the changes and pushes messages to Kafka topic. By default, separate topic will be created based on the tables in schemas.
Route SMT
By default, the topic name is created as <Server Name>.<Schema>.<Table Name> but this format is not recognised by the Jdbc Sink Connector. So we need to transform the topic name to a simples one <Table Name>.
| { | |
| “name”: “inventory-connector”, | |
| “config”: { | |
| “connector.class” : “io.debezium.connector.oracle.OracleConnector”, | |
| “tasks.max” : “1”, | |
| “database.server.name” : “server1”, | |
| “database.hostname” : “oracledb19”, | |
| “database.port” : “1521”, | |
| “database.user” : “c##dbzuser”, | |
| “database.password” : “dbz”, | |
| “database.dbname” : “ORCLCDB”, | |
| “database.pdb.name” : “ORCLPDB1”, | |
| “database.connection.adapter” : “logminer”, | |
| “database.history.kafka.bootstrap.servers” : “kafka:9092”, | |
| “database.history.kafka.topic”: “schema-changes.inventory”, | |
| “transforms”: “route”, | |
| “transforms.route.type”: “org.apache.kafka.connect.transforms.RegexRouter”, | |
| “transforms.route.regex”: “([^.]+)\\.([^.]+)\\.([^.]+)”, | |
| “transforms.route.replacement”: “$3” | |
| } | |
| } |
view rawregister-oracle-logminer.json
Filter SMT
Optionally you may include filter expression to filter events based on groovy expressions on the content.
"transforms": "filter",
"transforms.filter.type": "io.debezium.transforms.Filter",
"transforms.filter.language": "jsr223.groovy",
"transforms.filter.condition": "value.op == 'u',
"transforms.filter.topic.regex": "server1.DEBEZIUM.*",
This following connector ‘jdbc-sink’ is a Sink Connector which listens to the change events from the Kafka topics and pushes to PostgreSQL Database.
| { | |
| “name”: “jdbc-sink”, | |
| “config”: { | |
| “connector.class”: “io.confluent.connect.jdbc.JdbcSinkConnector”, | |
| “tasks.max”: “1”, | |
| “topics”: “CUSTOMERS,ORDERS,PRODUCTS,PRODUCTS_ON_HAND”, | |
| “connection.url”: “jdbc:postgresql://postgres:5432/inventory?user=postgresuser&password=postgrespw”, | |
| “transforms”: “unwrap”, | |
| “transforms.unwrap.type”: “io.debezium.transforms.ExtractNewRecordState”, | |
| “transforms.unwrap.drop.tombstones”: “false”, | |
| “auto.create”: “true”, | |
| “insert.mode”: “upsert”, | |
| “delete.enabled”: “true”, | |
| “pk.mode”: “record_key” | |
| } | |
| } |
curl -i -X POST -H “Accept:application/json” -H “Content-Type:application/json” http://localhost:8083/connectors/ -d @register-oracle-logminer.json
curl -i -X POST -H “Accept:application/json” -H “Content-Type:application/json” http://localhost:8083/connectors/ -d @jdbc-sink.json
Sample Database Operations
Initial Snapshot & Sync
By default, Oracle connector creates the read events from all tables and pushes to Kafka topics. This behaviour may be changed to setting “snapshot.mode” to “schema_only” where only initial sync will not happen.
Oracle Database

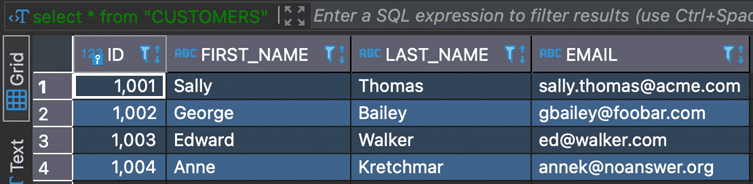
PostgreSQL Database
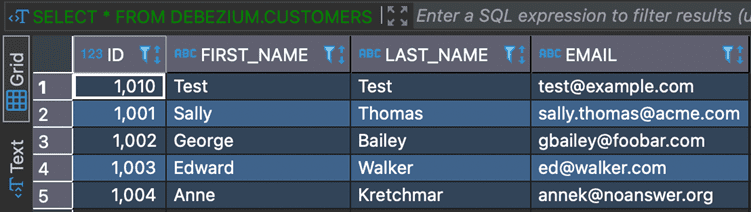
Insert Data in Oracle
INSERT INTO DEBEZIUM.CUSTOMERS VALUES (1010, ‘Test’, ‘Test’, ‘test@example.com’);
Oracle Database
CDC Event Generated
{
“schema”: {
“type”: “struct”,
“fields”: [
{
“type”: “struct”,
“fields”: [
{
“type”: “int16”,
“optional”: false,
“field”: “ID”
},
{
“type”: “string”,
“optional”: false,
“field”: “FIRST_NAME”
},
{
“type”: “string”,
“optional”: false,
“field”: “LAST_NAME”
},
{
“type”: “string”,
“optional”: false,
“field”: “EMAIL”
}
],
“optional”: true,
“name”: “server1.DEBEZIUM.CUSTOMERS.Value”,
“field”: “before”
},
{
“type”: “struct”,
“fields”: [
{
“type”: “int16”,
“optional”: false,
“field”: “ID”
},
{
“type”: “string”,
“optional”: false,
“field”: “FIRST_NAME”
},
{
“type”: “string”,
“optional”: false,
“field”: “LAST_NAME”
},
{
“type”: “string”,
“optional”: false,
“field”: “EMAIL”
}
],
“optional”: true,
“name”: “server1.DEBEZIUM.CUSTOMERS.Value”,
“field”: “after”
},
{
“type”: “struct”,
“fields”: [
{
“type”: “string”,
“optional”: false,
“field”: “version”
},
{
“type”: “string”,
“optional”: false,
“field”: “connector”
},
{
“type”: “string”,
“optional”: false,
“field”: “name”
},
{
“type”: “int64”,
“optional”: false,
“field”: “ts_ms”
},
{
“type”: “string”,
“optional”: true,
“name”: “io.debezium.data.Enum”,
“version”: 1,
“parameters”: {
“allowed”: “true,last,false,incremental”
},
“default”: “false”,
“field”: “snapshot”
},
{
“type”: “string”,
“optional”: false,
“field”: “db”
},
{
“type”: “string”,
“optional”: true,
“field”: “sequence”
},
{
“type”: “string”,
“optional”: false,
“field”: “schema”
},
{
“type”: “string”,
“optional”: false,
“field”: “table”
},
{
“type”: “string”,
“optional”: true,
“field”: “txId”
},
{
“type”: “string”,
“optional”: true,
“field”: “scn”
},
{
“type”: “string”,
“optional”: true,
“field”: “commit_scn”
},
{
“type”: “string”,
“optional”: true,
“field”: “lcr_position”
}
],
“optional”: false,
“name”: “io.debezium.connector.oracle.Source”,
“field”: “source”
},
{
“type”: “string”,
“optional”: false,
“field”: “op”
},
{
“type”: “int64”,
“optional”: true,
“field”: “ts_ms”
},
{
“type”: “struct”,
“fields”: [
{
“type”: “string”,
“optional”: false,
“field”: “id”
},
{
“type”: “int64”,
“optional”: false,
“field”: “total_order”
},
{
“type”: “int64”,
“optional”: false,
“field”: “data_collection_order”
}
],
“optional”: true,
“field”: “transaction”
}
],
“optional”: false,
“name”: “server1.DEBEZIUM.CUSTOMERS.Envelope”
},
“payload”: {
“before”: null,
“after”: {
“ID”: 1010,
“FIRST_NAME”: “Test”,
“LAST_NAME”: “Test”,
“EMAIL”: “test@example.com“
},
“source”: {
“version”: “1.8.1.Final”,
“connector”: “oracle”,
“name”: “server1”,
“ts_ms”: 1645967024000,
“snapshot”: “false”,
“db”: “ORCLPDB1”,
“sequence”: null,
“schema”: “DEBEZIUM”,
“table”: “CUSTOMERS”,
“txId”: “09002100b3020000”,
“scn”: “5494041”,
“commit_scn”: “5494042”,
“lcr_position”: null
},
“op”: “c”,
“ts_ms”: 1645967029112,
“transaction”: null
}
}
PostgreSQL Database
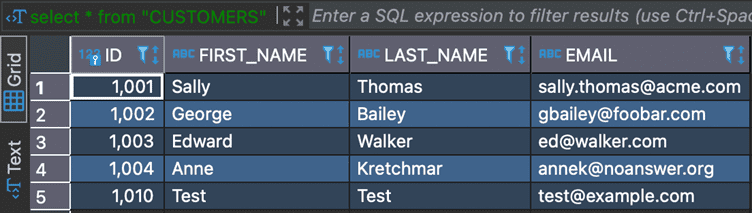
Update Data in Oracle
UPDATE DEBEZIUM.CUSTOMERS SET FIRST_NAME = ‘Sample’, LAST_NAME = ‘Sample’, EMAIL = ‘sample@example.com’ WHERE ID = 1010;
Oracle Database
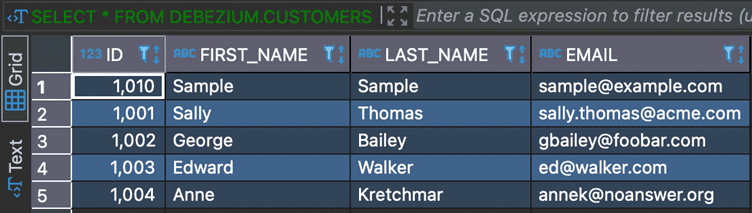
CDC Event Generated
{
“schema”: {
“type”: “struct”,
“fields”: [
{
“type”: “struct”,
“fields”: [
{
“type”: “int16”,
“optional”: false,
“field”: “ID”
},
{
“type”: “string”,
“optional”: false,
“field”: “FIRST_NAME”
},
{
“type”: “string”,
“optional”: false,
“field”: “LAST_NAME”
},
{
“type”: “string”,
“optional”: false,
“field”: “EMAIL”
}
],
“optional”: true,
“name”: “server1.DEBEZIUM.CUSTOMERS.Value”,
“field”: “before”
},
{
“type”: “struct”,
“fields”: [
{
“type”: “int16”,
“optional”: false,
“field”: “ID”
},
{
“type”: “string”,
“optional”: false,
“field”: “FIRST_NAME”
},
{
“type”: “string”,
“optional”: false,
“field”: “LAST_NAME”
},
{
“type”: “string”,
“optional”: false,
“field”: “EMAIL”
}
],
“optional”: true,
“name”: “server1.DEBEZIUM.CUSTOMERS.Value”,
“field”: “after”
},
{
“type”: “struct”,
“fields”: [
{
“type”: “string”,
“optional”: false,
“field”: “version”
},
{
“type”: “string”,
“optional”: false,
“field”: “connector”
},
{
“type”: “string”,
“optional”: false,
“field”: “name”
},
{
“type”: “int64”,
“optional”: false,
“field”: “ts_ms”
},
{
“type”: “string”,
“optional”: true,
“name”: “io.debezium.data.Enum”,
“version”: 1,
“parameters”: {
“allowed”: “true,last,false,incremental”
},
“default”: “false”,
“field”: “snapshot”
},
{
“type”: “string”,
“optional”: false,
“field”: “db”
},
{
“type”: “string”,
“optional”: true,
“field”: “sequence”
},
{
“type”: “string”,
“optional”: false,
“field”: “schema”
},
{
“type”: “string”,
“optional”: false,
“field”: “table”
},
{
“type”: “string”,
“optional”: true,
“field”: “txId”
},
{
“type”: “string”,
“optional”: true,
“field”: “scn”
},
{
“type”: “string”,
“optional”: true,
“field”: “commit_scn”
},
{
“type”: “string”,
“optional”: true,
“field”: “lcr_position”
}
],
“optional”: false,
“name”: “io.debezium.connector.oracle.Source”,
“field”: “source”
},
{
“type”: “string”,
“optional”: false,
“field”: “op”
},
{
“type”: “int64”,
“optional”: true,
“field”: “ts_ms”
},
{
“type”: “struct”,
“fields”: [
{
“type”: “string”,
“optional”: false,
“field”: “id”
},
{
“type”: “int64”,
“optional”: false,
“field”: “total_order”
},
{
“type”: “int64”,
“optional”: false,
“field”: “data_collection_order”
}
],
“optional”: true,
“field”: “transaction”
}
],
“optional”: false,
“name”: “server1.DEBEZIUM.CUSTOMERS.Envelope”
},
“payload”: {
“before”: {
“ID”: 1010,
“FIRST_NAME”: “Test”,
“LAST_NAME”: “Test”,
“EMAIL”: “test@example.com“
},
“after”: {
“ID”: 1010,
“FIRST_NAME”: “Sample”,
“LAST_NAME”: “Sample”,
“EMAIL”: “sample@example.com“
},
“source”: {
“version”: “1.8.1.Final”,
“connector”: “oracle”,
“name”: “server1”,
“ts_ms”: 1645967651000,
“snapshot”: “false”,
“db”: “ORCLPDB1”,
“sequence”: null,
“schema”: “DEBEZIUM”,
“table”: “CUSTOMERS”,
“txId”: “08001400ea020000”,
“scn”: “5542287”,
“commit_scn”: “5542288”,
“lcr_position”: null
},
“op”: “u”,
“ts_ms”: 1645967653034,
“transaction”: null
}
}
PostgreSQL Database
Monitoring Dashboard
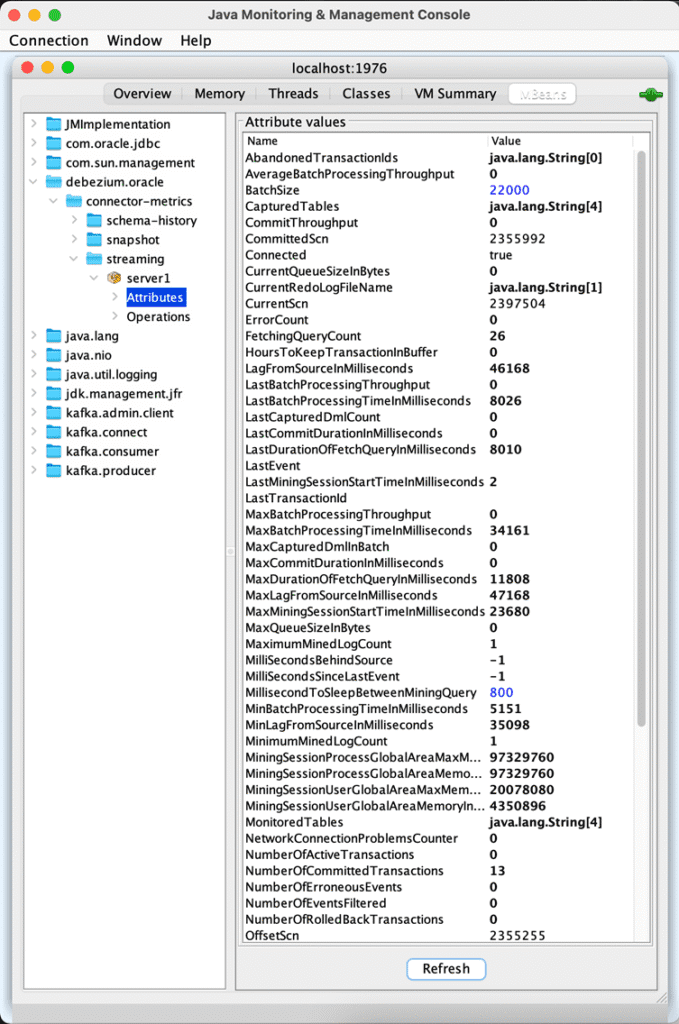
Runtime statistics are exposed by JMX MBEAN from Debezium connector docker image.
jconsole (localhost:1976)
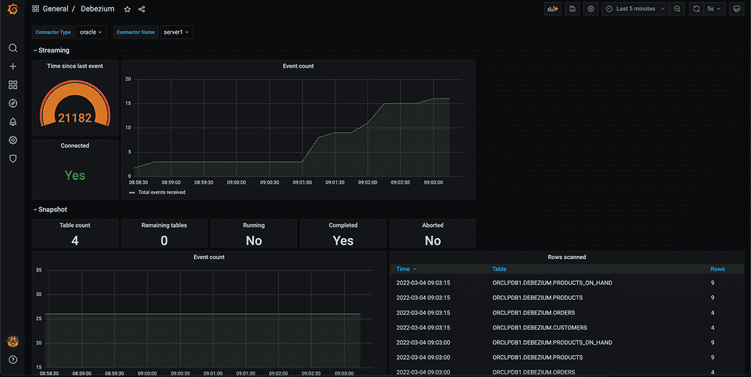
Grafana Dashboard (localhost:3000 (admin/admin))
All JMX MBEANs attributes are pushed to Prometheus. Following is the basic dashboard which shows few interesting statistics about the snapshot & stream.
Conclusion
Debezium is an industry standard tool for data replication between one database to another database/storages. It has both source & destination/sink connectors to make sure it connects almost all storage systems. The regular data replication needs no coding at all and can done with configurations only, the above POC application can be setup & run in less than 10 mins to test the features of Debezium. Running Debezium in production system may need more involved process setup to make sure availability, fault tolerance & recovery from a catastrophic failure








