
Background
In the era of big data, businesses are increasingly relying on real-time data processing to gain insights, make informed decisions, and enhance customer experiences. The ability to process and analyze data as it flows in is crucial for staying competitive in today’s data-driven landscape.
In this article, apart from exploring a robust and scalable solution for real-time data processing using Amazon Managed Streaming for Apache Kafka (MSK), Confluent Schema Registry, and Apache Spark Streaming within AWS Glue ETL, my utmost focus will be on ensuring compatibility & feasibility with Avro schema records using cross platform components like AWS services & confluent services, a popular data serialization format in the Apache Kafka ecosystem. There are abundant articles on real time streaming for json records using MSK & GSR (Glue schema registry) but didn’t find anything with confluent schema registry on aws services, hence penning down the article to solve this problem as well.
Amazon MSK, a fully managed Kafka service, provides the backbone for ingesting and streaming data. It simplifies the setup and management of Kafka clusters, allowing organizations to focus on their data and applications rather than infrastructure. Follow the article to do the MSK setup https://docs.aws.amazon.com/msk/latest/developerguide/getting-started.html
Confluent Schema Registry is a critical component for managing schemas and ensuring data compatibility in a Kafka environment. It provides a central repository for schema versioning and validation, enabling seamless data evolution without disrupting downstream consumers. Follow this link for more information https://docs.confluent.io/platform/current/schema-registry/index.html
AWS Glue ETL, a fully managed ETL service, empowers data engineers and scientists to build scalable and high-performance ETL pipelines. When combined with Spark Streaming, it becomes a powerful tool for real-time data processing.
Throughout this article, we will delve into the intricacies of handling Avro records using confluent schema registry and perform aggregation in real time & publish data into dynamo DB endpoint.
So, let’s embark on this journey to harness the power of Amazon MSK, Confluent Schema Registry, and Spark Streaming in AWS Glue ETL for real-time data processing with Avro records compatibility.
Background
Assume an use case where CDC publisher gets data from Oracle tables (can be any data source). When there are changes to the tables from the redo logs and continuously pushing them to MSK Kafka topics which is being installed in EC2 machine. These data being published to Kafka topics are Avro records and the schema for them is defined in confluent schema registry which is installed in same EC2 machine and integrated with the Kafka publisher. This can be done by informatica power exchange or Kafka connect from confluent or in another way. Schema can be changed anytime as per source table schema(Oracle) dynamically and to defined them manually while doing streaming is not a suitable approach as it doesn’t support schema evolution in this way. Now we need to get those published data from the topics and ingest them into aws dynamo DBs by performing various aggregation on top of it in real time for down stream consumption.
Pain Points to tackle are:
— Real time processing (dealt in this example)
— Data loss prevention if the job failed (Checkpointing doesn’t work seamlessly here using s3 as storage option, there will be slowness in handling the commits & offsets) (Hence explicit Offset handling being used with respect to time and passed that to startingOffset option in spark read stream)
— Auto recovery (Glue config for retrial option)
— Schema evolution support (illustrated in this example)
— Late arrival of data (Handled in error handling part)
Tech Stack
- Python
- Apache Kafka
- Apache Spark
- AWS Glue
- AWS MSK
- AWS EC2
- Dynamo DB
- AWS S3
- Confluent (CSR)
- Athena
- Cloud watch
Simplified Process diagram
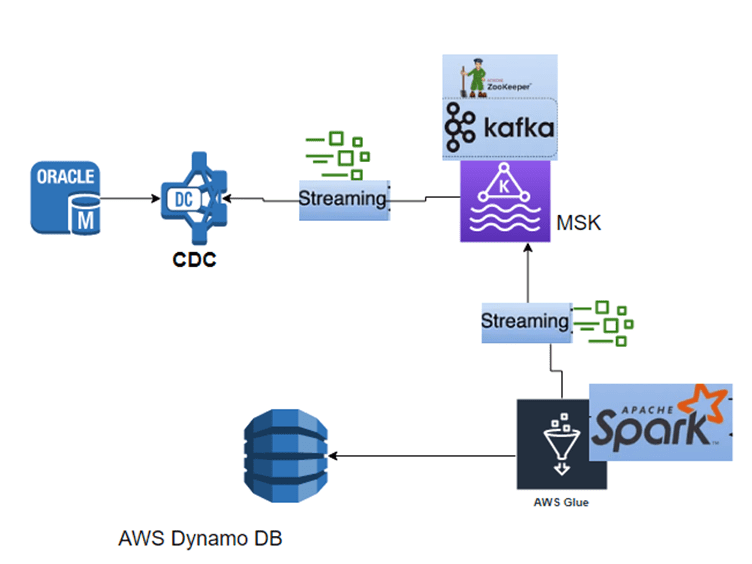
Detailed Architecture
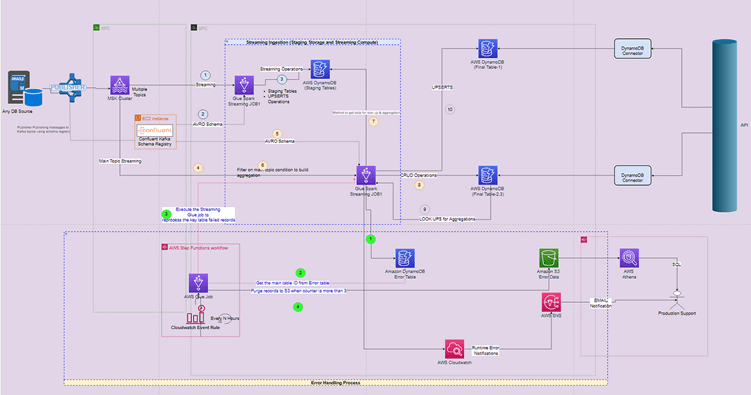
Process Flow Elaboration
steps:
- Set up MSK cluster using aws documentation using ec2 host for Kafka topics
- Brokers and zookeeper will be part of the MSK set up and will be managed by aws. But choose the size and partitions as per the best practices and project needs.
- Publisher published the messages to topics defined in publisher in this case per table using confluent schema registry
- One-to-One mapping for tables to topics. Any changes to the table schema will be auto populated in schema registry if any new records comes in to the respective topics
- Create a GLUE streaming job-1 (use spark streaming in job type config) to read Kafka topics data (Spark.readStream)
- Use schema registry client import from confluent to get latest schema from schema registry dynamically (implemented in the below code sample)
- Decode the topics spark data frame consisting Avro records using from_avro library by excluding first 5 magic bytes
- Then ingest the data into dynamo staging tables for each topics
- Use certain condition for driver main topic to get each record ID, in case any record in this topic flows in, then join other records from dynamo tables which has already ingested as part of this process and ingest final aggregated records to another final dynamo table for intended use.
- 2nd part is for error handling
- Incase any data is late or dependency doesn’t met in other topics, then publishing the main driver topic records to an error dynamo DB table
- After certain time run another glue batch job to pick these error records from error dynamo DB table and then join other records from all tables to build final record
- After 3 retrials if other tables dependency is missing then park these error records to s3 for further analysis
- Set up Athena and SNS alarm to notify quickly about any anomalies
Code Elucidation
- This method is to get the schema from confluent registry for all topics
- Get the URL from ec2 IP where the registry has been hosted
schema_cache = {}
## Getting Avro Schema dynamically from CSR
def get_latest_schema(topic_name, registry_url):
# Check if the schema is already cached
if topic_name in schema_cache:
return schema_cache[topic_name]
# Fetch the latest schema from the schema registry
schema_config = {“url”: registry_url}
schema_registry_client = schema_registry.SchemaRegistryClient(schema_config)
try:
schema = schema_registry_client.get_latest_version(topic_name + “-value”).schema.schema_str
except Exception as exception:
print(f”Error reading topic {topic_name} schema: {exception}”)
return None
# Cache the schema for future use
schema_cache[topic_name] = schema
return schema
- This is being used to stream all the topics data. Bootstrap servers details will be from MSK cluster details. SASL protocol has been used for port 9096 URL in bootstrap servers
- Some of the configs in the options is project specific like maxOffsetsPerTrigger, starting Offsets, max.poll.records, auto.offset.reset
expr(“substring(value,6,length(value))”) : This one has been used to get rid of the magic bytes of Avro records
def get_sparkdataframe_for_topics(kafka_topic_name,bootstrap_servers,offset,groupid,csr_schema):
groupid = groupid + str(int(time.time()))
df = spark \
.readStream \
.format(“kafka”) \
.option(“kafka.security.protocol”, “SASL_SSL”) \
.option(“kafka.sasl.mechanism”, “SCRAM-SHA-512”) \
.option(“kafka.sasl.jaas.config”, f”org.apache.kafka.common.security.scram.ScramLoginModule required username=\”{SECRT_USERNAME}\” password=\”{SECRT_PWD}\”;”) \
.option(“kafka.bootstrap.servers”, bootstrap_servers) \
.option(“subscribe”, kafka_topic_name) \
.option(“failOnDataLoss”,”false”) \
.option(“auto.offset.reset”, “latest”) \
.option(“enable.auto.commit”, “false”) \
.option(“max.poll.records”, “10000”) \
.option(“startingOffsets”, “latest”) \
.option(“kafka.group.id”, groupid) \
.option(“maxOffsetsPerTrigger”, “10000”) \
.load()
## This is being used get avro values after excluding magic bytes
df = df.withColumn(“formatted_value”,expr(“substring(value,6,length(value))”))
return df
- Below code has been used to parse the Avro records in the data frame. Permissive is used to eradicate the junk records and not to encounter with the job failures.
from_avro_options= {“mode”:”PERMISSIVE”}
topic_df = batch_df.withColumn(“message”, from_avro(“formatted_value”, csr_schema,from_avro_options))
- Data frame to RDD and RDD to DF conversion has been used here to insert the records into dynamo DB tables in a robust way. So that there will not be any duplicates error while ingesting or any failures.
- Based on each record another python utility has been called to ingest the data into various dynamo staging tables and then aggregate them based on certain conditions in real time.
- To use different methods of your own python utility, import the below statement like this and then use that while calling the method.
import dynamodbLookup_Agrregation as dynamo_utility
dynamo_utility.methd_for_aggregation(response, db_con, config_context)
- Main glue JOB-1 sample code for your reference. (modify & reuse as per your use case)
import os
import sys
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
from pyspark.sql.types import *
import time
from awsglue.context import GlueContext
from awsglue.job import Job
from awsglue.utils import getResolvedOptions
from pyspark.context import SparkContext
from pyspark.sql import SparkSession
import pyspark.sql.functions as psf
from pyspark.sql.types import *
import io
from datetime import datetime
from pyspark.sql.avro.functions import from_avro, to_avro
import json
from json import dumps
from decimal import Decimal
from io import BytesIO
from awsglue import DynamicFrame
import confluent_kafka
from confluent_kafka import schema_registry
import boto3
from functools import partial
from types import SimpleNamespace
from pyspark.sql.functions import lit,unix_timestamp
from collections import Counter
import dynamodbLookup_Agrregation as dynamo_utility
import ast
print(“******Welcome to SPARK real time STREAMING****************”)
dynamodb_conn = boto3.resource(“dynamodb”)
search_key = ‘date’
search_key1 = ‘period’
## Get these variables from the glue job arguments as per your project need
BUCKET_NAME = getResolvedOptions(sys.argv, [‘BUCKET_NAME’])[‘BUCKET_NAME’]
CONFIG_FILE_NAME = getResolvedOptions(sys.argv, [‘CONFIG_FILE_NAME’])[‘CONFIG_FILE_NAME’]
KEY_STR = getResolvedOptions(sys.argv, [‘KEYSTR’])[‘KEYSTR’]
## Used AWS secret manager to store the username & passwords
secretsKey = getResolvedOptions(sys.argv, [‘secretsKey’])[‘secretsKey’]
CHECKPOINT = getResolvedOptions(sys.argv, [‘CHKPNT_PATH’])[‘CHKPNT_PATH’]
client=boto3.client(“secretsmanager”,region_name=”XXXXX”)
response = client.get_secret_value(SecretId=secretsKey)
secretDict=ast.literal_eval(response.get(‘SecretString’))
SECRT_USERNAME=secretDict.get(‘username’)
SECRT_PWD=secretDict.get(‘password’)
## Calling the method from the utility written for dynamo DB ingstion and aggregation
config_context = dynamo_utility.get_table_config_from_from_file(BUCKET_NAME, CONFIG_FILE_NAME, “aws”)
args = getResolvedOptions(sys.argv, [‘JOB_NAME’])
sc = SparkContext()
log_level = getResolvedOptions(sys.argv, [‘LOG_LEVEL’])[‘LOG_LEVEL’]
sc.setLogLevel(log_level if log_level is not None else ‘INFO’)
glueContext = GlueContext(sc)
job = Job(glueContext)
job.init(args[‘JOB_NAME’], args)
spark = glueContext.spark_session
logger = glueContext.get_logger()
logger.info(“info message”)
logger.warn(“warn message”)
logger.error(“error message”)
# Enable backpressure for Spark Streaming
spark.conf.set(“spark.streaming.backpressure.enabled”, “true”)
spark.conf.set(“spark.streaming.kafka.maxRatePerPartition”, “5000”)
# Set the default parallelism based on the number of Kafka partitions
spark.conf.set(“spark.default.parallelism”, str(8))
##get the relevant configs from s3 using json namespace
def get_json_namespace_from_s3():
key: str = KEY_STR
bucket_name = BUCKET_NAME
try:
s3 = boto3.client(‘s3’)
data = s3.get_object(Bucket=bucket_name, Key=key)[‘Body’].read()
json_content = json.loads(data, object_hook=lambda d: SimpleNamespace(**d))
except Exception as e:
print(f”Error reading key {key} from bucket {bucket_name}: {e}”)
logger.info(“ERROR READING BUCKET = ” + key + bucket_name )
raise
else:
print(f”Got object from S3″)
return json_content
schema_cache = {}
## Getting Avro Schema dynamically from CSR
def get_latest_schema(topic_name, registry_url):
# Check if the schema is already cached
if topic_name in schema_cache:
return schema_cache[topic_name]
# Fetch the latest schema from the schema registry
schema_config = {“url”: registry_url}
schema_registry_client = schema_registry.SchemaRegistryClient(schema_config)
try:
schema = schema_registry_client.get_latest_version(topic_name + “-value”).schema.schema_str
except Exception as exception:
print(f”Error reading topic {topic_name} schema: {exception}”)
return None
# Cache the schema for future use
schema_cache[topic_name] = schema
return schema
## Spark streaming for kafka source
def get_sparkdataframe_for_topics(kafka_topic_name,bootstrap_servers,offset,groupid,csr_schema):
groupid = groupid + str(int(time.time()))
df = spark \
.readStream \
.format(“kafka”) \
.option(“kafka.security.protocol”, “SASL_SSL”) \
.option(“kafka.sasl.mechanism”, “SCRAM-SHA-512”) \
.option(“kafka.sasl.jaas.config”, f”org.apache.kafka.common.security.scram.ScramLoginModule required username=\”{SECRT_USERNAME}\” password=\”{SECRT_PWD}\”;”) \
.option(“kafka.bootstrap.servers”, bootstrap_servers) \
.option(“subscribe”, kafka_topic_name) \
.option(“failOnDataLoss”,”false”) \
.option(“auto.offset.reset”, “latest”) \
.option(“enable.auto.commit”, “false”) \
.option(“max.poll.records”, “10000”) \
.option(“startingOffsets”, “latest”) \
.option(“kafka.group.id”, groupid) \
.option(“maxOffsetsPerTrigger”, “10000”) \
.load()
## This is being used get avro values after excluding magic bytes
df = df.withColumn(“formatted_value”,expr(“substring(value,6,length(value))”))
return df
def replace_none(rdd_dict):
# checking for dictionary and replacing if None
if isinstance(rdd_dict, dict):
for key in rdd_dict:
if rdd_dict[key] is None:
rdd_dict[key] = “”
else:
replace_none(rdd_dict[key])
# checking for list, and testing for each value
elif isinstance(rdd_dict, list):
for val in rdd_dict:
replace_none(val)
#This method is being used for ingestion & aggregation which is usage specific. You can use youe own logic
def process_record(r, db_con) -> None:
response = dynamo_utility.method_for_ingestion(r, db_con, config_context)
if response[“no_of_errors”] == 0:
dynamo_utility.methd_for_aggregation(response, db_con, config_context)
def write_to_table(dynamodb_conn,df, table_name, columnnames, topicname):
now = datetime.now()
dt_string = now.strftime(“%d-%m-%Y %H:%M:%S”)
glue_time = {‘glue_staging_time’: dt_string}
filtered_df=df.select(*columnnames)
records=filtered_df.rdd.map(lambda row: row.asDict()).collect()
for onerow in records:
replace_none(onerow)
dict_lower = {k.lower(): v for k, v in onerow.items()}
if(any(x!=”” for x in dict_lower.values())):
print(“*******Record Insertion for topic*****”+topicname)
dict_lower.update(glue_time)
rdd = sc.parallelize([dict_lower])
spark_df=rdd.toDF()
result_df=DynamicFrame.fromDF(spark_df, glueContext, “result_df”)
glueContext.write_dynamic_frame.from_options(
frame=result_df,
connection_type=”dynamodb”,
connection_options={
“dynamodb.output.tableName”: table_name,
“dynamodb.throughput.write.percent”: “1.5”,
“dynamodb.output.retry”: “30”
}
)
print(dict_lower)
if table_name != None and “main_driving_table” in table_name:
if “XXXXX” in dict_lower and bool(dict_lower[“XXXXX”]):
process_record(dict_lower, dynamodb_conn)
def ingest_to_dynamo_db(json_tbl_config,topicname,csr_schema):
def stream_writefunc(batch_df, batch_id):
# used to handle junk data
from_avro_options= {“mode”:”PERMISSIVE”}
topic_df = batch_df.withColumn(“message”, from_avro(“formatted_value”, csr_schema,from_avro_options))
source_columns = json_tbl_config.column_names
updated_source_columns = map(lambda s: “message.”+ s, source_columns)
write_to_table(dynamodb_conn,topic_df,json_tbl_config.target_table_name,updated_source_columns,topicname)
return partial(lambda a, b: stream_writefunc(a, b))
def get_allschema_dict_objcet(appconfig):
all_schema_dict={}
for tblconfig in appconfig.tables:
all_schema_dict[tblconfig.topic_name] = get_latest_schema(tblconfig.topic_name,appconfig.schema_registry_url)
return all_schema_dict
def preprocess_dataframe_for_ingestion(app_config,csr_allschema):
for tbl_config in app_config.tables:
csr_schema=csr_allschema.get(tbl_config.topic_name)
if csr_schema is not None and csr_schema:
df=get_sparkdataframe_for_topics(tbl_config.topic_name,app_config.kafka_bootstrap_servers,app_config.startingOffsets,app_config.consumer_group_id,csr_schema)
df.writeStream.foreachBatch(ingest_to_dynamo_db(tbl_config,tbl_config.topic_name,csr_schema)).start()
application_config = get_json_namespace_from_s3()
csr_schemadictionary= get_allschema_dict_objcet(application_config)
preprocess_dataframe_for_ingestion(application_config,csr_schemadictionary)
spark.streams.awaitAnyTermination()

Use the above conig in glue job for confluent kafka library import. Import the wheel file by storing it in S3
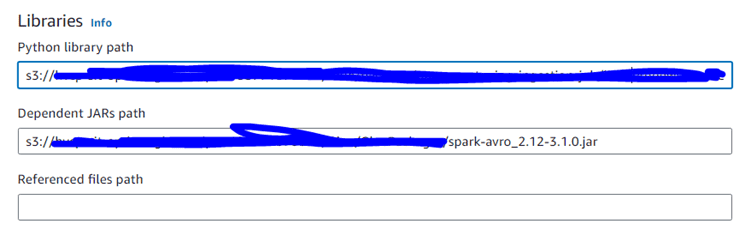
Use the above config in glue for external jar and python utlity
Compatibility challenges
- Integrating AWS services with aws Glue Schema registry will be comparatively more easier rather than with confluent schema registry.
- In this case, I have to import proper confluent .whl file from CSR repo and then import that as binary in the glue job parameter section of the config.
- As Avro records comes with key and value pair, there will be lots of hindrances if we don’t handle & parse them carefully. In this case its been done using Spark Avro library.
- Most importantly, we need to skip the magic bytes which is not necessary.
Conclusion
There are several effective approaches to address this specific use case. In the above sections, I have demonstrated a practical prototype that I’ve developed to tackle this challenge. I hope this elucidation will provide valuable insights and solutions for similar scenarios.








