Large Data Volumes (LDV) in Salesforce is an imprecise, elastic term. These large data volumes(LDV) can lead to sluggish performance, including slower queries, slower search and list views, and slower sandbox refreshing.
Why is LDV important?
Under the hood
Salesforce Platform Structure
- Metadata Table: describe custom objects and fields
- Data Table: containing the physical records in your org
- Virtual Database: A virtualization layer which combines the data and metadata to display the underlying records to the User
- Platform takes the SOQL entered by the user which is converted to native SQL under the hood to perform necessary table joins and fetch the required information.
How does Search Work?
- Record takes 15 minutes to be indexed after creation.
- Salesforce searches the Index to find records.
- Found rows are narrowed down using security predicates to form Result Set.
- Once Result-Set reaches a certain size, additional records are discarded.
- ResultSet is used to query the main database to fetch records.
Skinny Tables
What is a skinny table?
Condensed table combining a shortlist of standard and custom fields for faster DB record fetches.
Key Facts
- Salesforce stores standard and custom field data in separate DB Tables
- Skinny table combines standard and custom fields together
- Data fetch speed is improved with more rows per fetch.
- Do not contain soft-deleted records
- Best for > 1M records
- Immediately updated when master tables are updated
- Usable on standard and custom objects
- Created by Salesforce Support
Indexing Principles
What is an index?
- Sorted column, or combination of columns which uniquely identify rows of data.
- Index contains sorted column and pointers to the rows of data.
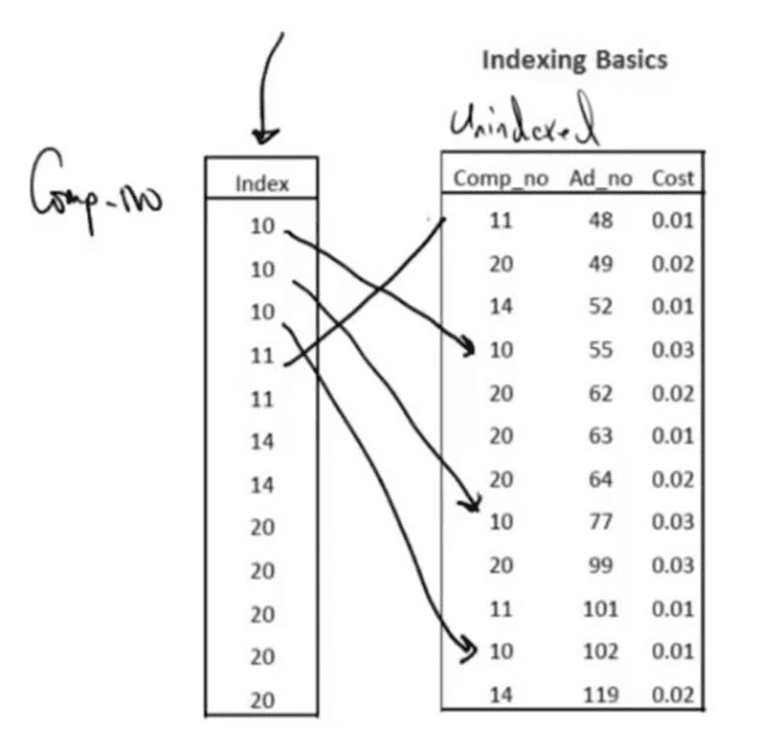
Standard vs Custom Index

Best Practices
How should we improve performance under Large Volumes?
- Aim to use indexed fields in the WHERE clause of SOQL queries
- Avoid using NULLS in queries as index cannot be used
- Only use fields present in skinny table
- Use query filters which can highlight < 10% of the data
- Avoid using wildcards in queries, such as % as this prevents use of an index
- Break complex query into simple singular queries to use indexes
- Select ONLY required fields in SELECT statement
Ownership Skew
When you have more than 10,000 records for a single object owned by a single owner.
Why does this cause problems?
- Share Table Calculations: When you move a user in the Role Hierarchy, sharing calculations need to take place on large volumes of data to grant and revoke access.
- Moving users around the hierarchy, causes the sharing rules to be re-calculated for both the user in the hierarchy, and any users above this user in the role hierarchy.
How can we avoid this?
- Data Migration: Work with client to divide records up across multiple real end-users
- Integration User: Avoid making integration user the record owner
- Leverage Lead and Case assignment rules
- If unavoidable: assign records to a user is an isolated role at the top of the Role Hierarchy
Ownership Skew
When you have more than 10,000 records for a single object owned by a single owner.
Why does this cause problems?
- Share Table Calculations: When you move a user in the Role Hierarchy, sharing calculations need to take place on large volumes of data to grant and revoke access.
- Moving users around the hierarchy, causes the sharing rules to be re-calculated for both the user in the hierarchy, and any users above this user in the role hierarchy.
How can we avoid this?
- Data Migration: Work with client to divide records up across multiple real end-users
- Integration User: Avoid making integration user the record owner
- Leverage Lead and Case assignment rules
- If unavoidable: assign records to a user is an isolated role at the top of the Role Hierarchy
Sharing Considerations
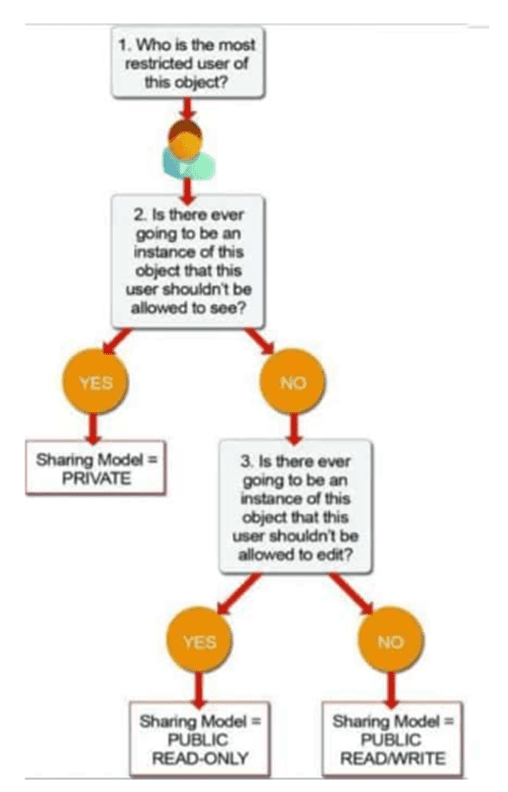
Org Wide Defaults
What should I do
- Set OWDs to Public R/W and Public R/O where possible for non-confidential data
- Reduce the requirement for a share table.
- Use ‘Controlled by Parent’ to avoid additional share tables
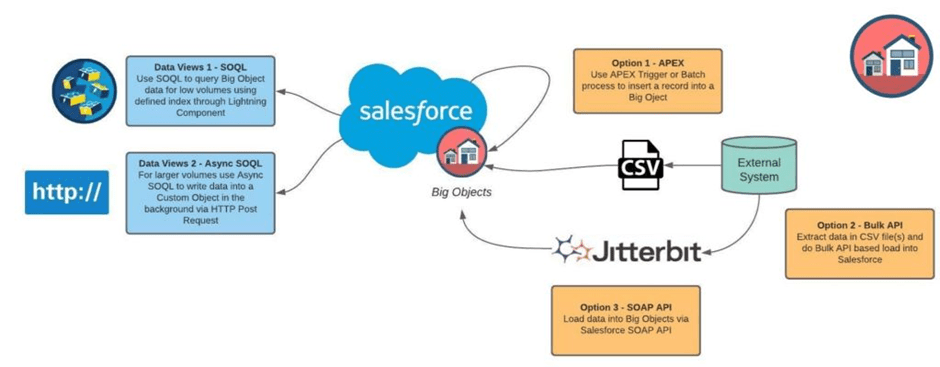
Data Load Strategy
1. Approach- Middleware Led
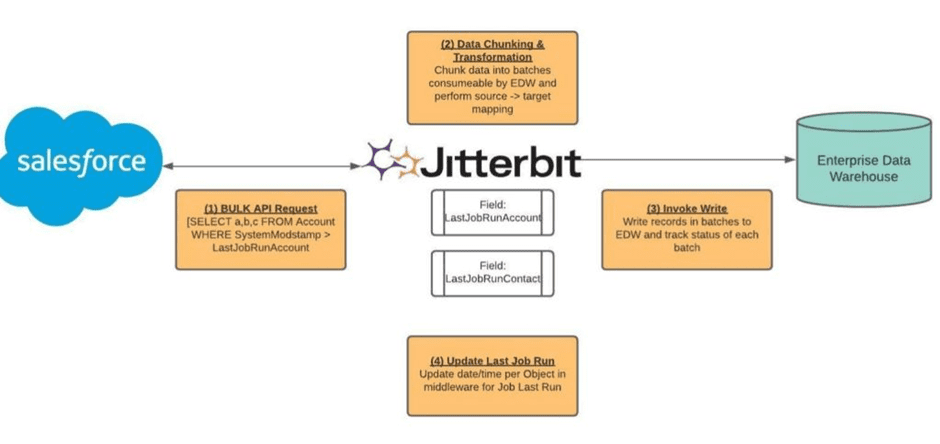
2. Approach- Using Heroku?
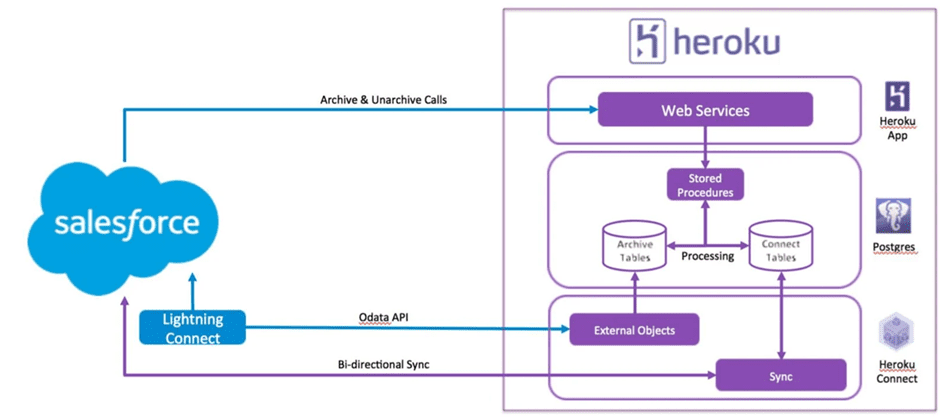
3. Approach – Big Objects