

In this post, I will show you how to easily chat with your images using Google’s Gemini AI. I will also show you how you can build your own image chat application using Gemini’s API.
Introduction to Gemini
Google Gemini is a family of large language models, also known as conversational AI or chatbot, developed by Google DeepMind. It is a successor to previous models like LaMDA and PaLM 2, aiming to compete with similar models like OpenAI’s GPT-4.
Here’s a quick overview of Gemini:
- Launched: December 6th, 2023
- Purpose: To answer your questions, assist with writing, planning, learning, and more, similar to a chatbot or search engine.
- Versions: Three versions exist, catering to different needs: Gemini Ultra, Pro, and Nano.
- Capabilities: It can process information across various formats like text, image, video, and code, making it “multimodal.”
Gemini is the best way to get direct access to Google AI.
Now that we have an overview of Gemini, let us use it to interact with images. To do so, you will need to create a Google account, if you do not have one already.
Next, go to https://gemini.google.com/app/ to access Gemini’s chat interface that looks like this:
Great! Now, we can upload an image and ask questions of the image. To do so, click the image icon in the prompt area of the interface and upload any image of your choice from your local computer. When that is uploaded, simply ask questions about the image.
Here is an example:
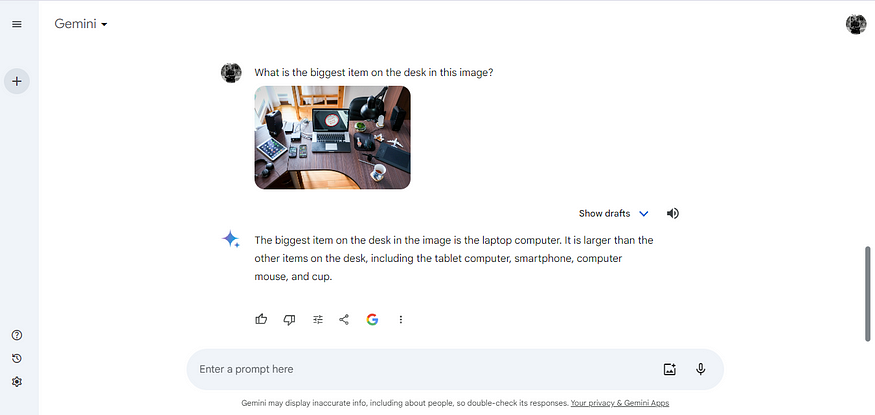
In the above example, I uploaded an image of an office desk hosting different productivity tools. I then asked Gemini to identify the biggest item on the desk in the image, which it correctly identified as the laptop computer. This way, you can upload an image and interact with it. The only drawback is that you need to keep exposing the image to Gemini in order to keep interacting with it. Gemini does not seem to store the image in its chat history.
Nevertheless, we will work around that problem in the next section where we write Python code to call Gemini’s API and then build our own chat interface.
Python Code
Here, we will build a web frontend that will enable us to use Gemini to interact with an image. You can find the complete code for this project at this GitHub repository. First, though, you will need to login to Google AI Studio to retrieve your Gemini API key. When that is done, you will need to install the the google-generativeai Python library and other dependencies by running the code below in your terminal:
pip install google-generativeai grpcio grpcio-tools gradio
Next, we will need to import the libraries:
import google.generativeai as genai
import gradio as gr
That having been done, we will now load the gemini-pro-vision model, which we will use to interact with images:
# load vision model
model = genai.GenerativeModel("gemini-pro-vision")
With the model loaded, let us test it by asking it questions about this image

# loading Image
import PIL.Image
img = PIL.Image.open("gitara-pianino-muzyka.jpg")
# analyzing image
response = model.generate_content([img, "what is the guitar placed on top of?"])
# printing the response
print(response.text)
# The guitar is placed on top of a piano.
As you can see from the above response, the vision model did a good job analyzing the image and generating the correct response. Because gemini-pro-vision is a multimodal model, it can analyze an image based on a text prompt and return a text output as well. Let’s now build the web frontend for this project.
Gradio Frontend
To build the frontend using Gradio, we will need to write the prediction function that will be passed to the Gradio method:
import numpy as np
import PIL.Image
def ImageChat(image, prompt):
# load model
model = genai.GenerativeModel("gemini-pro-vision")
# check image file and convert to a Numpy array
if isinstance(image, np.ndarray):
img = PIL.Image.fromarray(image)
else:
img = PIL.Image.open(image)
response = model.generate_content([prompt, img])
return response.text
The code above first loads the model, then it converts the image into a NumPy array before passing it to the model.generate_content() method to generate a response. Next, we will write the code for the frontend:
app = gr.Interface(ImageChat,
inputs = [gr.Image(), gr.Text()],
outputs = gr.Text(),
title = "Image Chat",
theme = gr.themes.Soft())
app.launch()
What we have simply done is to pass the function to the gr.Interface()method, then define the inputs (image and text) and outputs (text) of the application, give it a title, and set a theme for it. When you run the above code, you should see a simple interface that looks like this:
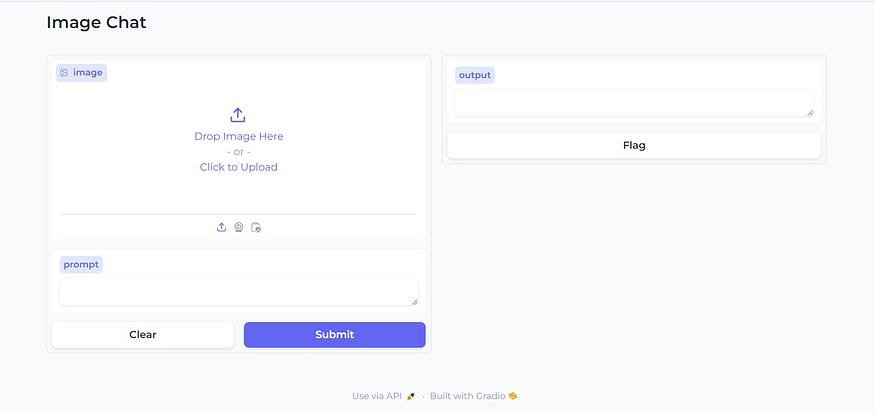
Now you can upload an image and ask questions about the image. This web frontend can be hosted on Hugging Face as a space, but that is beyond the scope of this post. Nevertheless, you can interact with a hosted version of this web application here.
Let’s try an example:
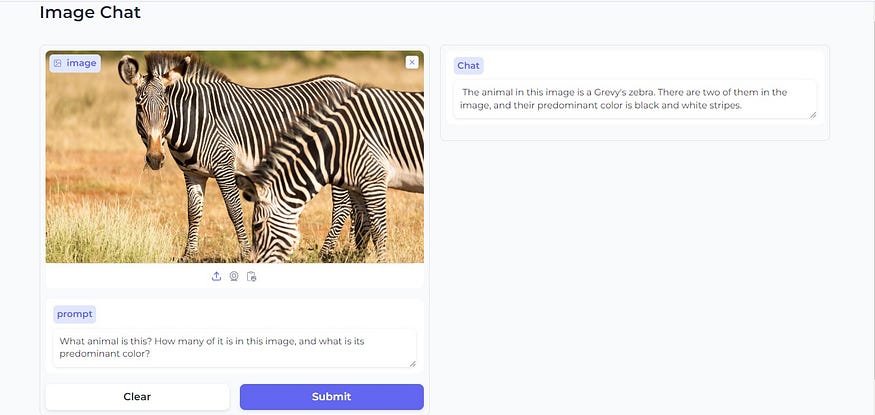
Here, we uploaded the above image and asked it the following questions:
“What animal is this? How many of it is in this image, and what is its predominant color?”
And it gave the following response:
The animal in this image is a Grevy’s zebra. There are two of them in the image, and their predominant color is black and white stripes.
Recap
Google’s Gemini AI models are robust multimodal models that have many capabilities, including computer vision and text generation. And when both capabilities are combined, you can create an image analyzing service like has been demonstrated in this post.
You can use Gemini either by visiting its URL https://gemini.google.com/app/ or by accessing its API if you are a developer. The future seems bright with Google Gemini, and it would be interesting to see what other kinds of products are built on top of Gemini.







